昭和生まれシニアデザイナーのデザイン事務所
よろずデザイン処 佐々木商店
MAIL: info@sasakishop.com
【江戸文化研究】『くずし字AI-OCR』なるものとは?

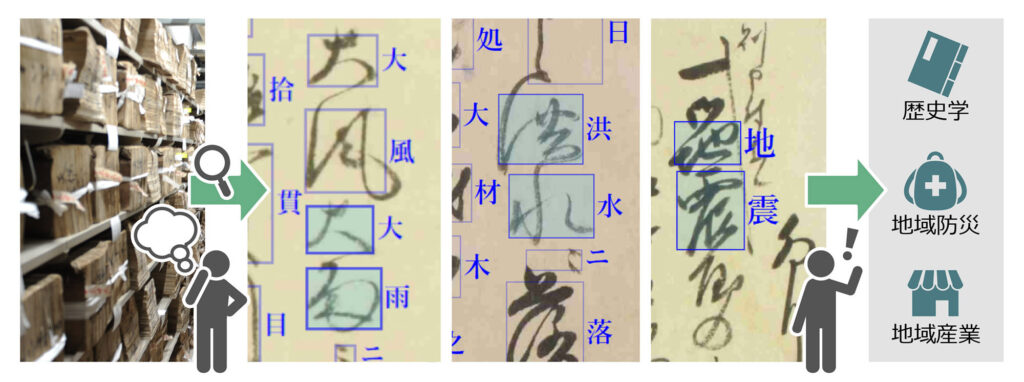
筆文字はおろか普段のペン字ですら上手いとは言いがたい店長の字ですが、世の中には一見何を書いているのか分からないような、「くずし字」なるものが存在しているのは知っていました。昔の公文書は、楷書もしくは草書や行書などで書かれていて判別はそれなりに可能なのですが、私的な古文書などは、それこそミミズがのたくったような判別不可能な文字が多いようで、時々専門家によって◯◯のくずし字が解読された、ということがニュースになったりします。
ところが、先日、熊本大学とTOPPANが共同で「くずし字AI-OCR」を活用した古文書の大規模調査のための独自手法を開発した、との記事を見つけて、そうか、AIもここまできたか、とワケの分からん地味な感動を覚えたものです。しかもその対象が、専門家でも解読が困難な難易度の高いくずし字で書かれた歴史資料『細川家文書(ほそかわけもんじょ)』です。
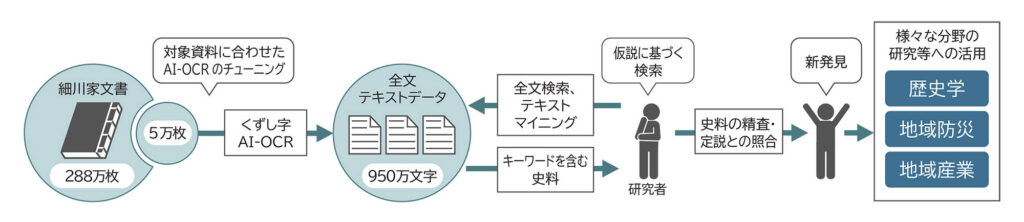
画像①はその細川家文書の一部ですが、いやぁ、読めないことハンパないですね。これをAI学習したOCR(光学的文字認識)機能で、文書の288万枚のうち5万枚の解読に成功したというから、すごいです(画像②)。なんせ古文書のほとんどはくずし字なので、これが活用されることによって加速度的に過去の歴史が紐解かれるスピードが増すことは間違いありません。(画像③はそのフロー図)
手書き文字の判別がしづらい人は現代でもいますし、過去から現在までのそんな記録が明らかになっていく、ということに多少のロマンを感じる店長でした。
(注)今回の画像はすべて熊本大学とTOPPANのホームページからのものです。興味のある方は、各サイトをご覧ください。
※この投稿を気に入った方は「いいね!」、もしくはコメントを頂けると、とっても嬉しいです!